在VS2017中实现混合高斯模型的详细步骤与应用实例分析
本文旨在详细探讨如何在Visual Studio 2017中实现混合高斯模型,包括相关的步骤和应用实例分析。首先,我们将从混合高斯模型的基本概念入手,解析其数学背景及实际应用场景。接着,将具体介绍在VS2017中搭建开发环境、实现模型的步骤,以及代码编写与调试过程中的注意事项。此外,我们还将通过一个实际案例来展示混合高斯模型的有效性,最后总结其优缺点以及未来的研究方向。整篇文章不仅适合对机器学习感兴趣的读者,也为希望在实际项目中运用该技术的人提供了实用指导。
1、混合高斯模型基础知识
混合高斯模型是一种常见的概率模型,广泛应用于数据聚类和模式识别等领域。该模型是由多个高斯分布组成,每个高斯分布代表数据集中某一特征的潜在分布情况。这种方法能够有效捕捉数据中的复杂结构,使得我们可以从中提取有价值的信息。
该模型的重要参数包括各个组件的均值、协方差矩阵以及每个组件的权重。在实际应用中,通过EM(期望最大化)算法进行参数估计,可以确保我们找到最优解。同时,选择合适数量的高斯成分也是成功实施混合高斯模型的重要因素之一。
除了理论知识外,混合高斯模型还有众多实际应用。例如,在图像处理领域,它可以用于图像分割;在金融分析中,则可用于风险评估等。因此,对其理解能够帮助我们更好地利用这项技术解决现实问题。
2、VS2017环境搭建
为了在Visual Studio 2017中实现混合高斯模型,首先需要安装必要的软件包和库。推荐使用C++作为开发语言,这样能够充分利用其性能优势。在VS2017中,可以通过NuGet包管理器方便地添加所需依赖,例如Eigen库,这对于矩阵操作至关重要。
其次,我们需要创建一个新的项目,并设置相应的工程属性,以确保编译器能够正确识别头文件和库文件的位置。在此过程中,还需配置C++标准,以避免因不兼容导致的问题。例如,可以选择C++14或更新版本以支持较新的语法特性。
最后,为了提高代码质量和效率,可以考虑使用一些工具插件,如Code Analysis和ReSharper。这些工具能够帮助我们发现潜在问题,提高代码可读性,从而加快开发进度。
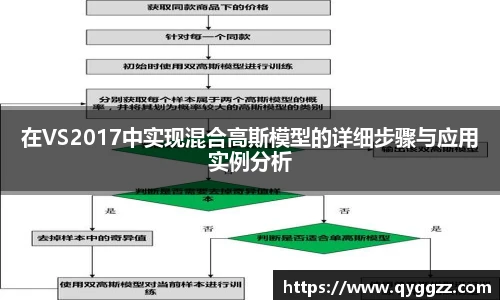
3、实现混合高斯模型
实现混合高斯模型主要包括初始化参数、执行EM算法以及最终优化结果三个步骤。首先,在初始化阶段,我们需要随机选择若干样本作为各个组件的初始均值,同时计算每个组件对应的数据点数目,以便后续迭代时更新权重。
接下来是EM算法核心部分,包括E步和M步。在E步中,根据当前参数计算每个样本属于各个高斯成分的概率;而在M步中,则根据这些概率重新计算均值、协方差及权重,并检查收敛条件,不断迭代直到达到预设精度或最大迭代次数为止。
最后,要对所得到的结果进行验证与可视化,以便直观了解聚类效果。可以通过绘制散点图并标记不同类别来体现各个组件对数据集划分的重要性,同时也能为后续分析提供依据。
4、案例分析与应用
以鸢尾花数据集为例,该数据集包含150个样本,每个样本由四个特征构成。在实施混合高斯模型之前,我们需要先对数据进行标准化处理,以消除量纲影响,提高算法准确性。本案例将展示如何利用前面提到的方法,对鸢尾花数据进行聚类分析。
首先,在VS2017环境下加载鸢尾花数据集,并进行必要的数据预处理,包括缺失值填充及特征缩放等步骤。随后,通过实施已设计好的EM算法,对数据进行训练,并观察训练过程中的参数更新变化情况,以判断收敛速度及稳定性。
经过几轮迭代后,我们得到了一组理想参数,并将结果可视化,与真实标签进行比较。从结果来看,聚类效果良好,不同种类之间有明显区分,这表明我们的实现是成功且有效的。此外,该方法还能扩展到其他具有类似结构的数据集中,为更多领域提供参考价值。
总结:
通过本文对“在VS2017中实现混合高斯模型”的详细阐述,我们深入了解了这一技术背后的原理与实践操作流程。从基础知识到环境搭建,再到具体实现与应用案例,无疑为广大机器学习爱好者提供了宝贵经验。这一过程不仅提高了我们的编程能力,还增强了对复杂统计学概念的理解。
未来,随着大数据技术的发展,混合高斯模型将在更多领域展现出其独特魅力。因此,不断探索和掌握这样的高级技术,将有助于推动相关研究向更深层次迈进。同时,我们也应关注新兴方法,如深度学习等,以拓宽思路,实现更好的问题解决方案。